
最近は「人間のドロドロした欲望をいかにスマートに表現するか」に脳のリソースを全振りしておりました。
世の中の「診断アプリ」って、ぶっちゃけお遊びでしょ?
「Aなら1点、Bなら2点」みたいな。
でも、BDSMっていうディープな世界をそんな低解像度で扱っちゃダメだろってことで、ガチの統計モデルを組もうとしたら意外と地獄を見たって話です。
性の嗜好を数式でデバックする
診断ロジックを組み始めた時、気づきました。
人間の性癖は「点数」じゃなくて「ベクトル(方向)」と「次元(多面性)」だってことに。
普通の心理テストが「おにぎりとパン、どっちが好き?」レベルだとしたら、僕が目指したのは「そのパンをどういうシチュエーションで、誰に、どんな顔で食べさせたいか(あるいは食べさせられたいか)」を納得いく制度で当てること。
気がついたら、コードの中に「Laplace Smoothing(ラプラススムージング)」とか「Network Scoring」なんて専門的な統計概念が並んでました。
【100問編】100次元の欲望をマッピングする地獄
最初は「質問が多ければ多いほど正確っしょ!」っていう、脳筋フルパワー思考からスタート。
まあ、元々はいつも使っていた診断サイトが急に韓国語になってみづらくなったから作り始めたのがキッカケでそのサイトが100問だったのもあるんだけど。
とりあえず脳死で100問を作り始めました。
100問は自分の経験を絞り出したり多種多様なのサイトを参考にしたり、知人に聞いたりしてベースを作って最終的にはGeminiと壁打ちをしまくりました。
質問は出来たはいいけど、その100問から性癖を導く変数を考え作成している際に、変数が多次元的に絡み合うカオスな設計図になることは分かってはいたものの、いざはじめるとなかなか大変。
たとえば「首を絞める」っていう一つのアクション。
これ、単なるサディズムじゃなくて、「相手の反応をじっくり見たい(観察)」「リードして支配したい(ドミナント)」「言葉を捨てて本能に従いたい(プライマル)」っていう、複数の属性が同時に存在している。
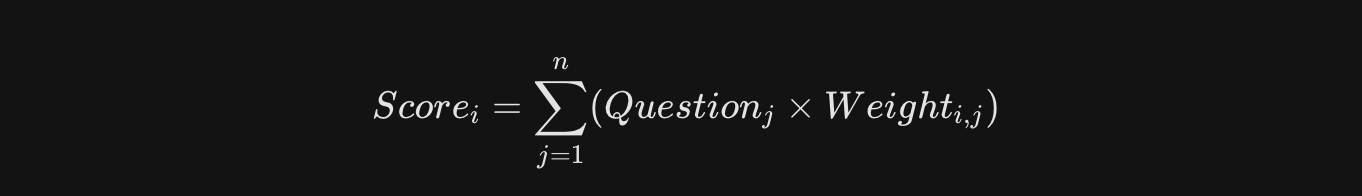
このn=100の行列を計算して、100次元の空間にユーザーをマッピングしようとしたわけです。
「主語」という名の地雷原
次にぶち当たったのが「言葉選び」の壁。
BDSMは「誰が・誰に・何をするか」がすべて。
助詞を一つ間違えるだけで、結果が180度ひっくり返る「反転の地獄」が待ってます。
- 「首を絞めるのが好き」(能動:S側)
- 「首を絞められるのが好き」(受動:M側)
これ、AIに質問文を作らせると、たまに気を利かせすぎて「首筋への刺激に強烈な興奮を覚える」とかいう、どっちとも取れるマイルドな表現に逃げやがるんですよね。
「違う!主語はこっちだ!」「もっと直接的に、でも品位は保て!」って、AIを相手に深夜までガスライティングまがいのプロンプト合戦。
正確さを求めると文章が長くなってユーザーが「読むのダル……」って離脱するし、短くすると「これ、どっちの意味?」っていう解釈の余白が生まれてしまう。
この「意味の分解能」と「ユーザー体験」のトレードオフもなかなか脳が溶ける作業でした。
とはいえ、大規模言語モデルの恩恵を多分に享受したのは間違い無いですね。
おかげさまで僕のGeminiちゃんは僕のことを変態だと思ってるに違いない。
【50問編】50問verを作り始めて精神崩壊しかけた
元々のサイトに16問を選ぶ項目があった。
でも、16問ではこの複雑な人間の嗜好を捉えるなんて不可能な話であり、16問の回答後に結局「何もわかりません」って結果が頻繁に返ってくる状態にすごく不満を持っておりました。
せっかく作るからには、短編であっても100問の精度に近づけたい!
30問にしようかとも80問にしようかとも考えてたけど、どちらも意味をなさないと結論が出た。
少なすぎても精度落ちるし、80問答えられる人は100問いけるでしょと。
でも、これが第2の地獄の始まりでした。
統計学的に言うと、質問を半分にする=データの「サンプリングレート(標本化頻度)」を半分にするってこと。
デジタル信号処理を知ってる人ならわかると思うけど、サンプリングレートを下げると「エイリアシング(折り返し雑音)」が発生する。
サンプリングレートを下げるというのは、「パラパラ漫画の枚数を極端に減らす」ようなものです。
例えば、本来の動きは右に全力でパンチを繰り出している(攻め)。サンプリング不足で、「構えた瞬間」と「振り切ってしゃがみ込んだ」の2枚しか絵がないと、その中間が見えなければ場合によっては「やられた」ように見えてしまう(受けへの誤認)。
これを診断テストに当てはめると、「質問数が少なすぎて、ユーザーの多面的な性格の『点』と『点』が変な風につながり、実像とは逆のキャラに見えてしまう」現象のことです。
つまり、本来なら「攻め」の波形なのに、データが飛び飛びすぎて「受け」の波形に誤認されちゃう現象。
しかも、問題が少なすぎるとたった1問の「あー、それもちょっと分かるかも」っていう中途半端な回答が、全体のスコアの20%を余裕で狂わせてくる。
これを防ぐために、特定の質問に「カスタム・ウェイト(重み)」を導入。 「この質問(言葉攻め)にYESなら、それはもう確定でデグレーダー(辱め)だろ」ってことで、重みを数倍にバフ盛り。 少ない質問数でいかに「死に属性」を作らずに、ユーザーの隠れた本性を炙り出すか。
パラメータを少し刻みでいじり続ける、泥沼のデバッグ作業が始まりました。
ラプラススムージングの導入
ここが一番の「技術の無駄遣い」ポイント。
質問数が少ないカテゴリ(たとえば「スイッチ」は3問しかない)だと、たった1問「7:非常に当てはまる」って答えただけで、適合率が即座に100%に張り付いちゃう。
これ、専門用語でいう「過学習)」に近い状態で、診断としての解像度が低すぎます。
そこで投入したのが、統計学のチート技「ラプラススムージング」。 別名、「幽霊質問」
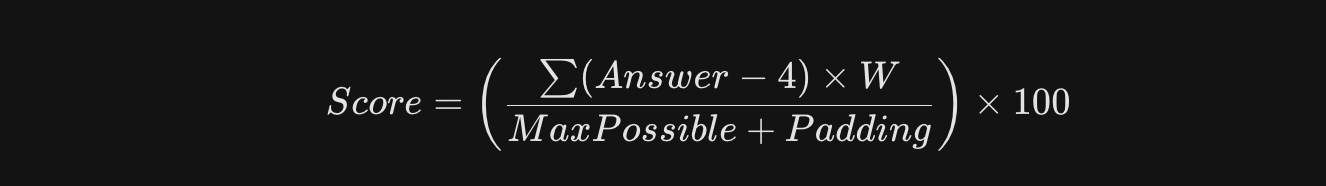
これ、何をしてるかっていうと、「まだ回答していない中立的な質問が、背後にあと数問ある」と仮定して計算させる。
こうすることで、分母が安定して、1〜2問の極端な回答でスコアが爆発するのを防げるって仕組みです。
さらに、50問版ではこの重りを進化させた 「動的パディング」 を実装しました。
// カテゴリの最大可能得点(MaxPossible)が低いほど、重りを重くする
if (isShortVersion && maxPossible < 8) {
padding += (8 - maxPossible) * 0.4;
}
質問数が少ない属性ほど、「幽霊たち」の抵抗が強くなります。
120%という極致に到達するには、この幽霊たちの沈黙を切り裂くほどの、圧倒的な「ガチ回答」を積み重ねなきゃいけない。
ユーザーに「優しく」50問に減らした分、裏側の数学的制約を「厳しく」することで、診断の「重み」と「説得力」を維持しました。
相関ロジックの実装
人間の性癖は、個別の独立したデータの集まりじゃない。それぞれが「引力」と「斥力(しりぞけ合う力)」を持って、複雑に絡み合う有向グラフです。
そこで実装したのが、「ネットワーク・スコアリング」っていう便利な相関ロジック。
たとえば、「ドミナント」のスコアがブチ上がっている人は、統計的に「マスター」や「サディスト」の素養も高いはず。
逆に、激しい「加虐(サディスト)」の数値が高いのに、同時に「バニラ」の数値がマックスなのは、ロジックとして矛盾が生じている可能性がある。
これを解決するために、以下の2つの隠しパラメータを叩き込んだ。
- ポジティブ相関
「ドミナント」が100%なら、隣接する「マスター」に自動で 8% のボーナスを飛ばす。
- ネガティブデバフ
相反する属性(サディストとバニラ、あるいはドミナントとサブミッシブ)には強力な「マイナスの重み」をかける。
// 相反する属性への排他ロジック
for (const [sourceKey, sourceScore] of Object.entries(normalizedScores)) {
if (sourceScore > 0) {
attr.negativeRelations.forEach(rel => {
// 例:ドミナント(80%) × 0.05 = -4% をサブミッシブから削り取る
finalScores[rel.target] -= sourceScore * rel.weight;
});
}
}
この「属性同士の押し引き」を調整し続けることで、診断結果から「中途半端なノイズ」を徹底的に排除しました。
最小最大120%の世界観と、ナチュラル属性。
元々使っていたサイトではMaxが150%でMinが-150%。
この考え方にはリスペクトをしており、プラスでもマイナスでも振り切っていた方がわかりやすいしキャッチー。
しかし、150%が最大値なのは個人的には美しさは感じていなかった。
今回の診断アルゴリズムでは120%に設定するとしっくりきた。
そして、今までにはなかった概念として忍び込ませたのは、 「Natural(天性)」 スコアからのブースト。
「教わったわけでもないのに、自然と体が動く」
「昔から、こういう関係性に惹かれていた」
そんな、知識や経験を超えた 「メタ認知」 が高いユーザーには、最大 1.08倍の乗算ボーナスが付与される設計としました。
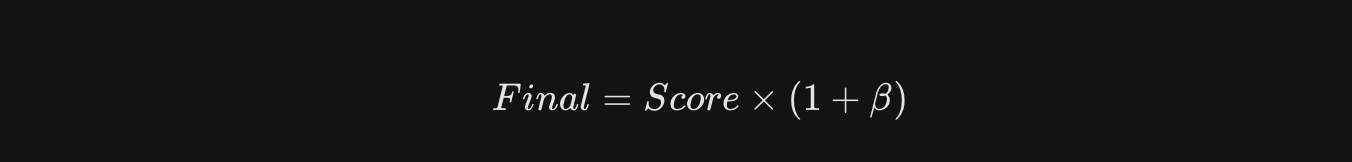
ベーススコアで 100%を叩き出し、かつ「自分はそういう性質の人間だ」という本能を確信している者はさらにブーストさせる仕組みです。
「あなたは枠に収まりきらない、本物の属性の権化ですよ」っていう、アルゴリズムからの最大級の敬意を表現できればと思いました。
さいごに。
今のロジックが「完璧」だとは全く思っていません。
だって、人間の心なんて銀河系より広いし、毎日変わるくらいデリケートなもん。
たった50問や100問の計算だけでみんなのすべてを解明できた気になるほど単純な話じゃない。
結局、このアルゴリズムをさらに進化させるのは、僕じゃなくてみなさんの「声」です。
実際にやってみて、「ここはマジで刺さった!」「これはちょっと違うかも」っていうフィードバックをガンガンぶつけていただけたらと思います。
それをもとに、僕は何度でもロジックをアップデートし続けます。
こんなところまで読んでくださった皆さま本当にお疲れ様。
この後に100問も質問に回答する元気残ってないよね、、笑
また元気な時に覗いてみてくださいね。
ではまた〜。
【追伸】「木を見て森を見ない」への追加アプデ
ブログを書き終えて一息ついた直後、もう一つ致命的な「人間心理のバグ」に気づいてしまいました。
とあるユーザーさんのシミュレーションをしていた時のこと。
その方は「お尻を叩かれること」に特化した質問には「非常にそう思う(7)」を連発し、「スパンキー(お仕置き好き)」属性が 90% を超える異常値に近いスコアを叩き出しました。
ところが、それ以外の「首を絞められる」とか「強烈な痛みを伴う拘束」みたいなハードな質問にはすべて「全くそう思わない(1)」と答えていたんです。
結構いるんですよね、こういうタイプ。
スパンキーだけど、痛みは嫌という一見矛盾にも感じられる性質。
しかし、人間はこんなもんです。
さて、今までのアルゴリズムの結果だとどうなったか?
アルゴリズムは無慈悲にも「スパンキー: 91%」「マゾヒスト(全体としてのM度): 1%」「サブミッシブ: 12%」という結果を返しました。
数学的には正しい。
M要素の多くを否定しているのだから、平均化すればMスコアは地に落ちる。
でも、人間的には絶対におかしいですよね。
お尻をひたすらピンポイントで叩かれるのが大好きな人間が、「あなたはM度1%のノーマルです」って言われたら「いやいや、絶対Mだろ!」って納得感がゼロになる。
点と点をつなぐだけでは、人間の自認を表現できない。
そこで急遽実装したのが、「末端の性癖から、上位の大分類への逆流」ロジックでした。
「他の痛いことは全部嫌いでも、お仕置きや拘束といった特定の属性が極端に高い場合は、そのエネルギーを大本の『マゾヒスト』や『サブミッシブ』へと強力に逆流させて加点する」
スパンキーのスコアの 15% を マゾヒスト に、10% を サブミッシブにそれぞれ直接流し込む。
この結果、先ほどの「スパンキー 91%」のユーザーさんは、自動的に「マゾヒスト 23%」「サブミッシブ: 24%」までスコアが持ち上がり、「特定のプレイに特化したマイルドなM」という、極めて腑に落ちるプロファイリングに着地しました。
他の痛いことや辱めは全部嫌い(否定)」であるため、マゾヒストが50%や80%になることはありませんが、人間的には納得感が得られる結果に。
細かい属性(木)が高まれば、自然と上位属性(森)も豊かになる。
人間の「自分はこういう人間だ」というラベル付けの手触りに、ようやくアルゴリズムが追いついてきた瞬間でした。
まだまだこれからもフィードバックを受けてアップデートしていきますよ〜。

